Visualizing and modeling relationships III
Lecture 12
EDA: AM I SCREAMING? capitalTotal
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.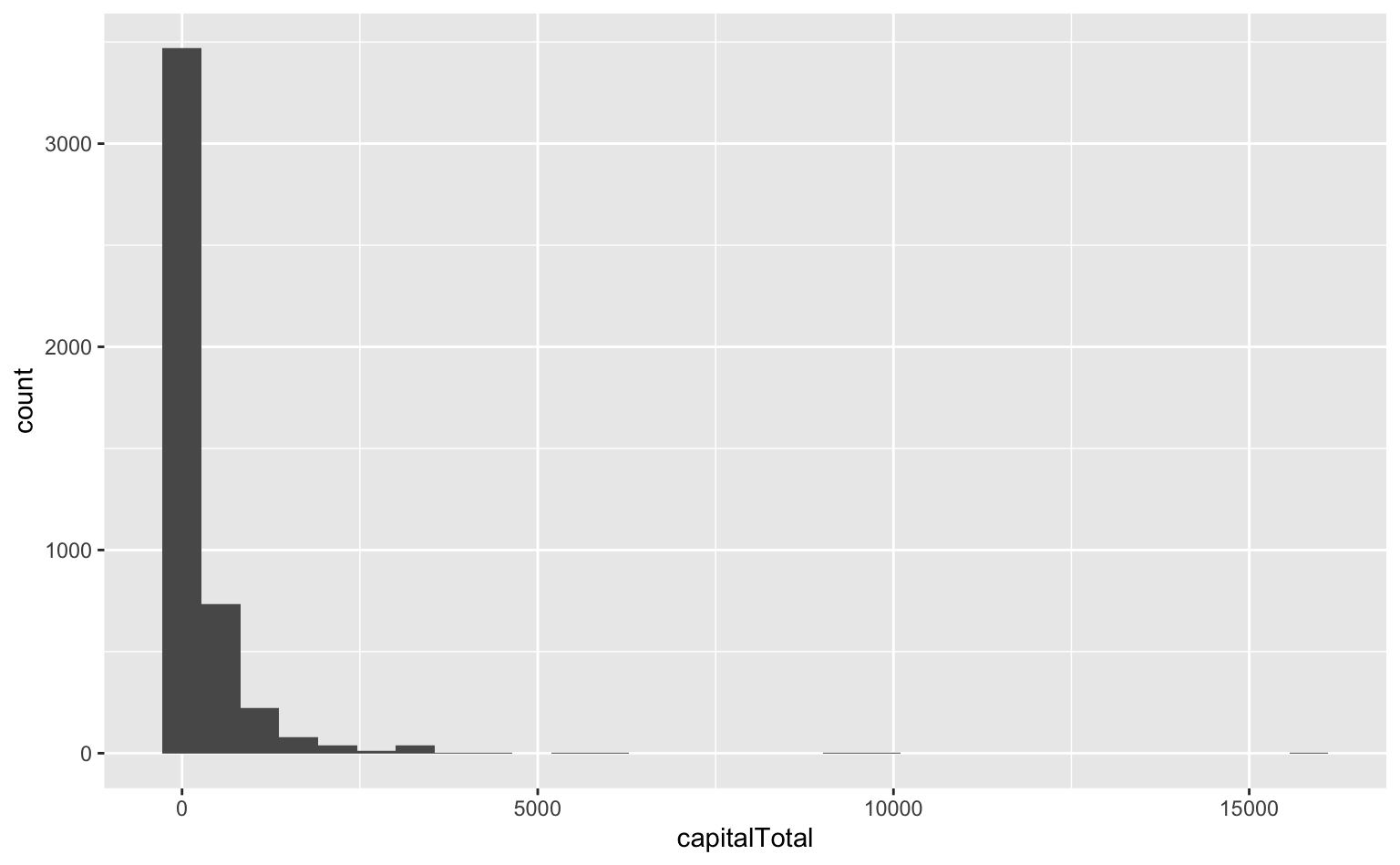
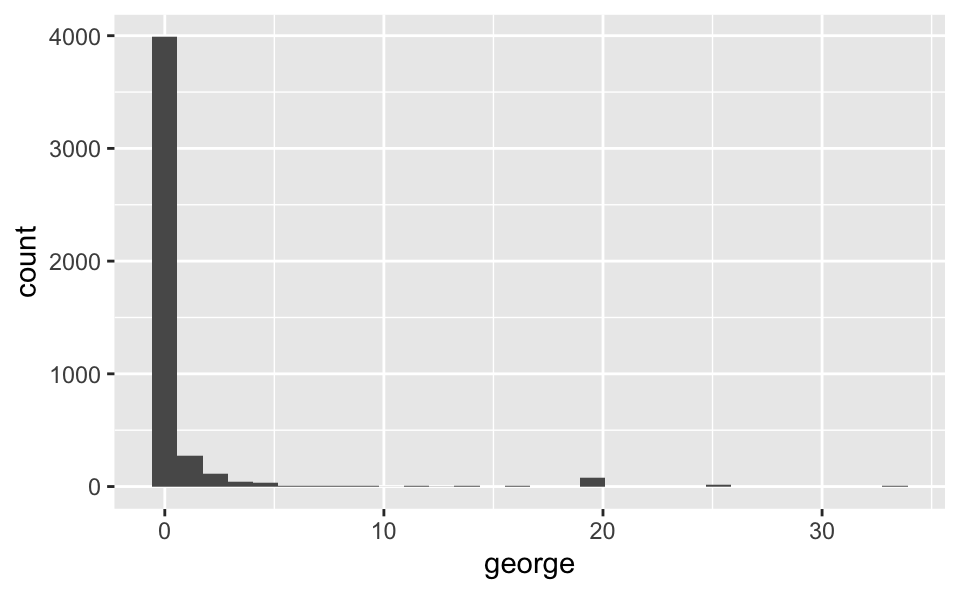
EDA: george, is that you?
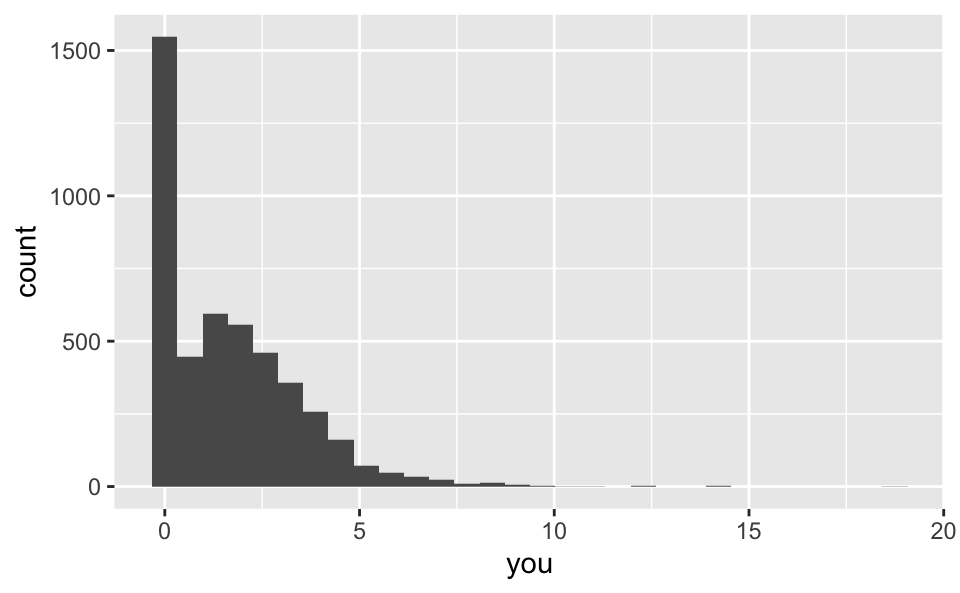
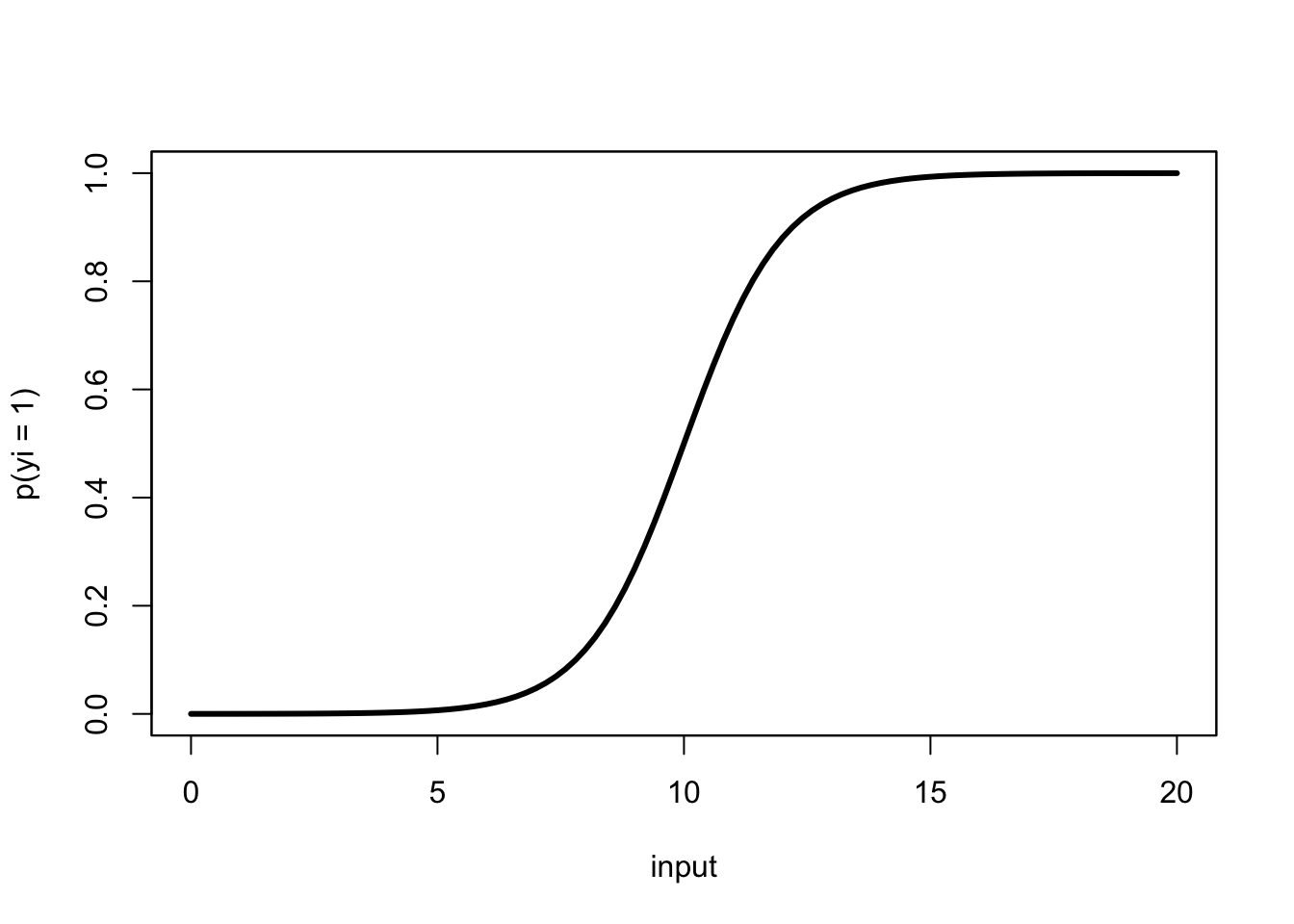
Logistic regression, visualized
ae-11-spam
Ultimate goal: Recreate the following visualization.
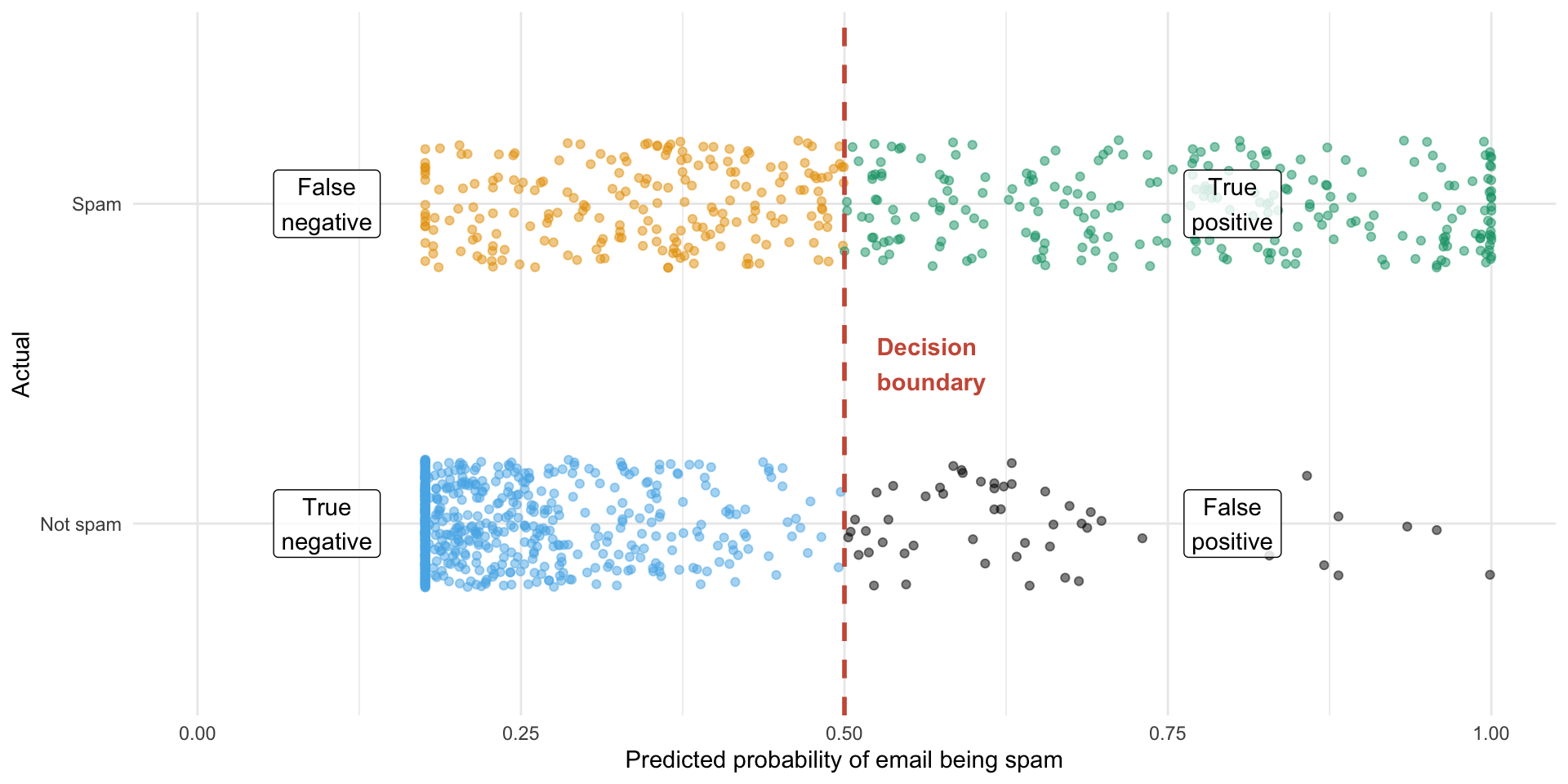
ae-11-spam
Reminder of instructions for getting started with application exercises:
- Go to the course GitHub org and find your
ae-11-spam(repo name will be suffixed with your GitHub name). - Click on the green CODE button, select Use SSH (this might already be selected by default, and if it is, you’ll see the text Clone with SSH). Click on the clipboard icon to copy the repo URL.
- In RStudio, go to File ➛ New Project ➛Version Control ➛ Git.
- Copy and paste the URL of your assignment repo into the dialog box Repository URL. Again, please make sure to have SSH highlighted under Clone when you copy the address.
- Click Create Project, and the files from your GitHub repo will be displayed in the Files pane in RStudio.
- Click ae-11-spam.qmd to open the template Quarto file. This is where you will write up your code and narrative for the lab.