Visualizing uncertainty II
Lecture 15
Duke University
STA 113 - Fall 2023
Warm-up
Announcements
- Project 2 proposal due tomorrow at 5 pm.
Confidence intervals
Packages
Airbnb in Asheville, NC
We have data on the price per guest (ppg) for a random sample of 50 Airbnb listings in 2020 for Asheville, NC. We are going to use these data to investigate what we would of expected to pay for an Airbnb in in Asheville, NC in June 2020.
Terminology
Population parameter - What we are interested in. Statistical measure that describes an entire population.
Sample statistic (point estimate) - describes a sample. A piece of information you get from a fraction of the population.
Catching a fish
Suppose you’re fishing in a murky lake. Are you more likely to catch a fish using a spear or a net?
- Spear \(\rightarrow\) point estimate
- Net \(\rightarrow\) interval estimate
Constructing confidence intervals
Quantifying the variability of the sample statistics to help calculate a range of plausible values for the population parameter of interest:
Via simulation \(\rightarrow\) using bootstrapping – using a statistical procedure that re samples a single data set to create many simulated samples.
Via mathematical formulas \(\rightarrow\) using the Central Limit Theorem
Bootstrapping, what?
The term bootstrapping comes from the phrase “pulling oneself up by one’s bootstraps”, which is a metaphor for accomplishing an impossible task without any outside help.
Impossible task: estimating a population parameter using data from only the given sample.
Note: This notion of saying something about a population parameter using only information from an observed sample is the crux of statistical inference, it is not limited to bootstrapping.
Bootstrapping, how?
- Resample with replacement from our data n times, where n is the sample size
- Calculate the sample statistic of interest of the new, resampled (bootstrapped) sample and record the value
- Do this entire process many many times to build the bootstrap distribution
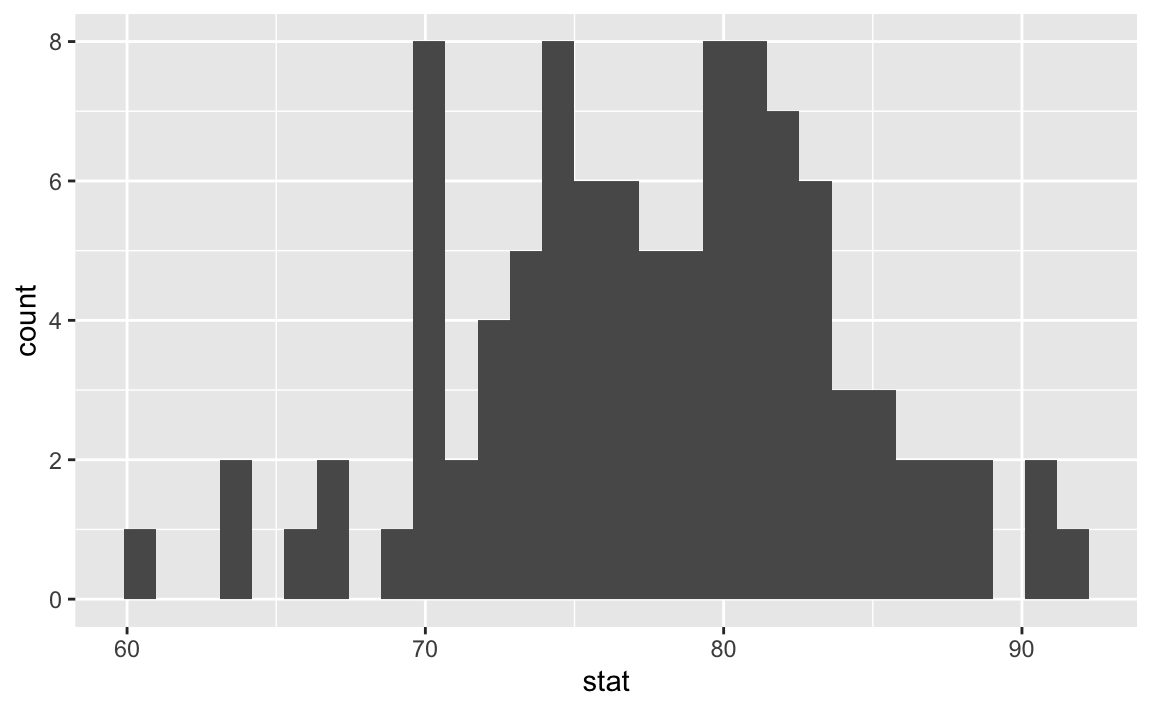
Bootstrapping Airbnb rentals
The bootstrap distribution
Visualzing the bootstrap distribution
What do you expect the center of the bootstrap distribution to be? Why? Check your guess by visualizing the distribution.
Calculating the bootstrap distribution
Interpretation
Which of the following is the correct interpretation of the bootstrap interval?
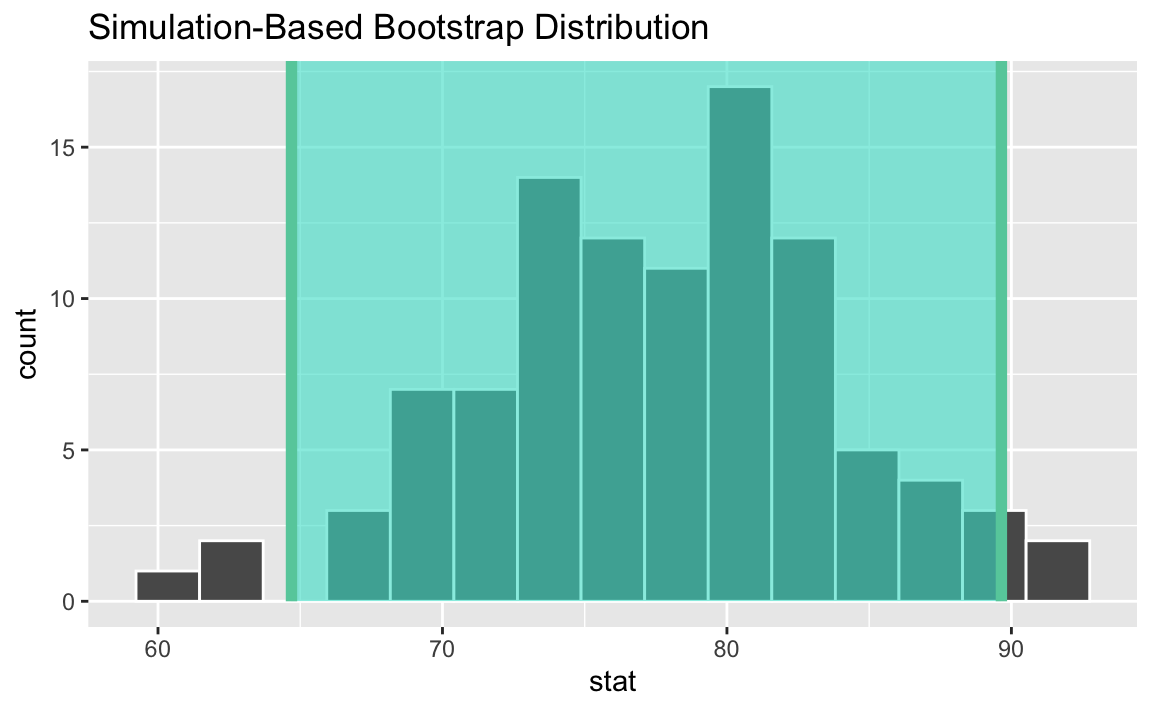
There is a 95% probability the true mean price per night for an Airbnb in Asheville is between $64.7 and $89.6.
There is a 95% probability the price per night for an Airbnb in Asheville is between $64.7 and $89.6.
We are 95% confident the true mean price per night for Airbnbs in Asheville is between $64.7 and $89.6.
We are 95% confident the price per night for an Airbnb in Asheville is between $64.7 and $89.6.
Leveraging tidymodels tools further
Calculating the observed sample statistic:
Leveraging tidymodels tools further
Calculating the interval:
Leveraging tidymodels tools further
Visualizing the interval:
![]()