Visual inference
Lecture 16
One of the pictures is a photograph of a painting by Piet Mondrian while the other is a photograph of a drawing made by an IBM 7094 digital computer. Which of the two do you think was done by the computer?
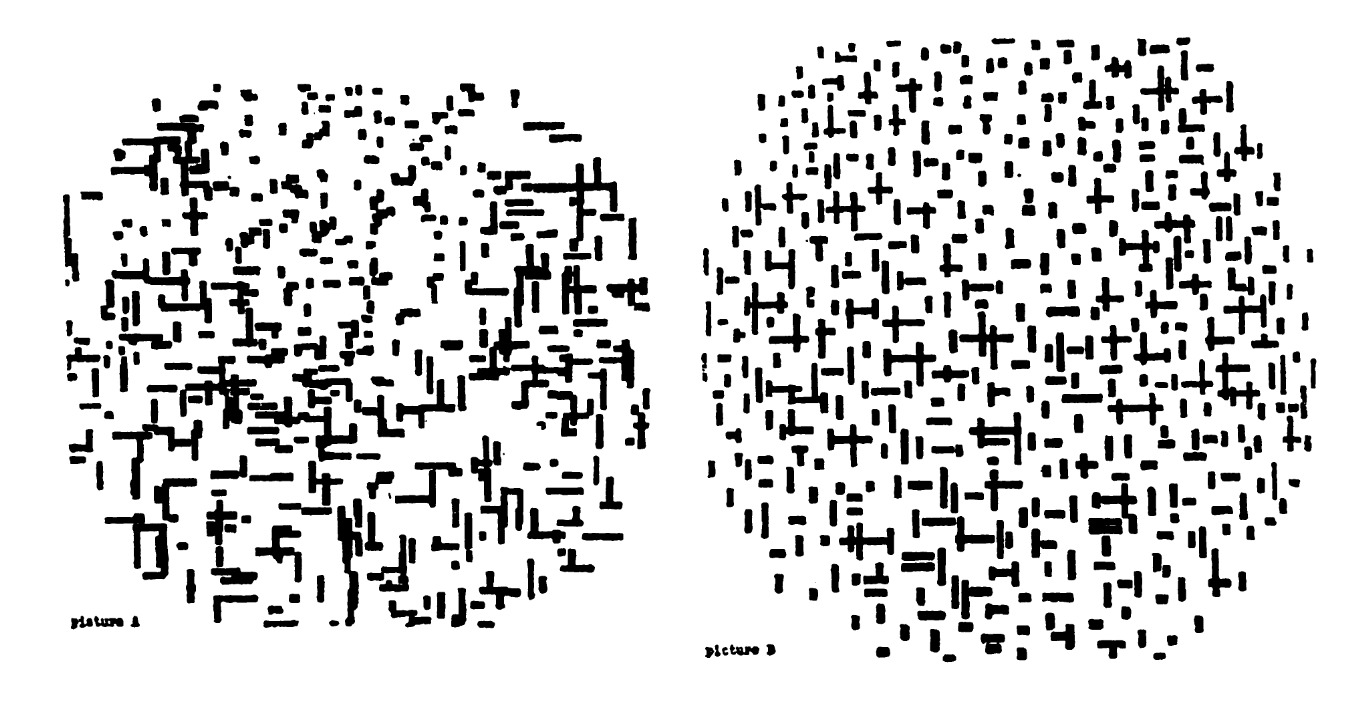
A. M. Noll, “Human or machine: A subjective comparison of piet mondrian’s”composition with lines” (1917) and a computer- generated picture,” The Psychological Record, vol. 16, pp. 1–10, 1966.
Aside: Who is Piet Mondrian?

Apophenia
What is apophenia?
The tendency to perceive a connection or meaningful pattern between unrelated or random things.

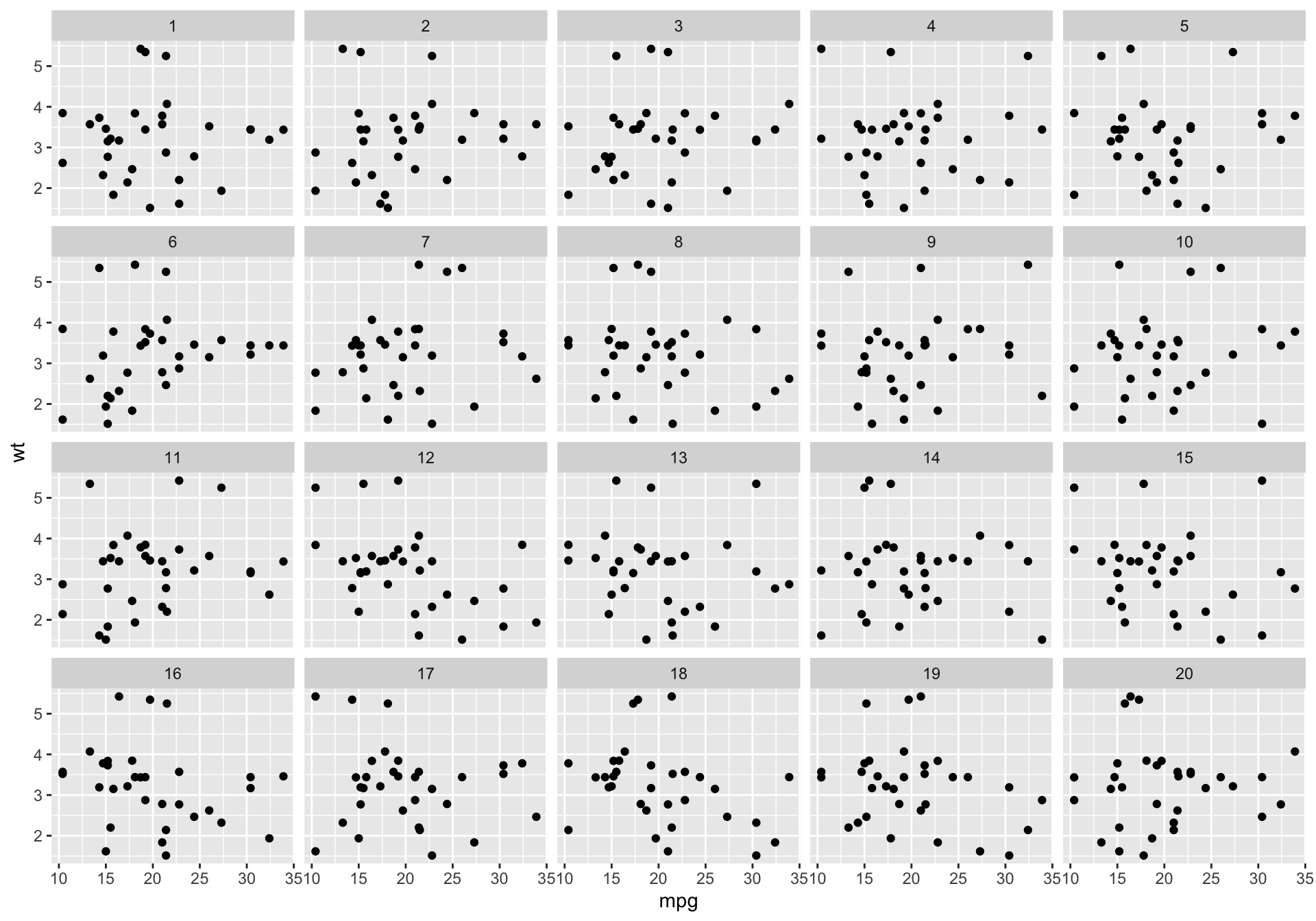
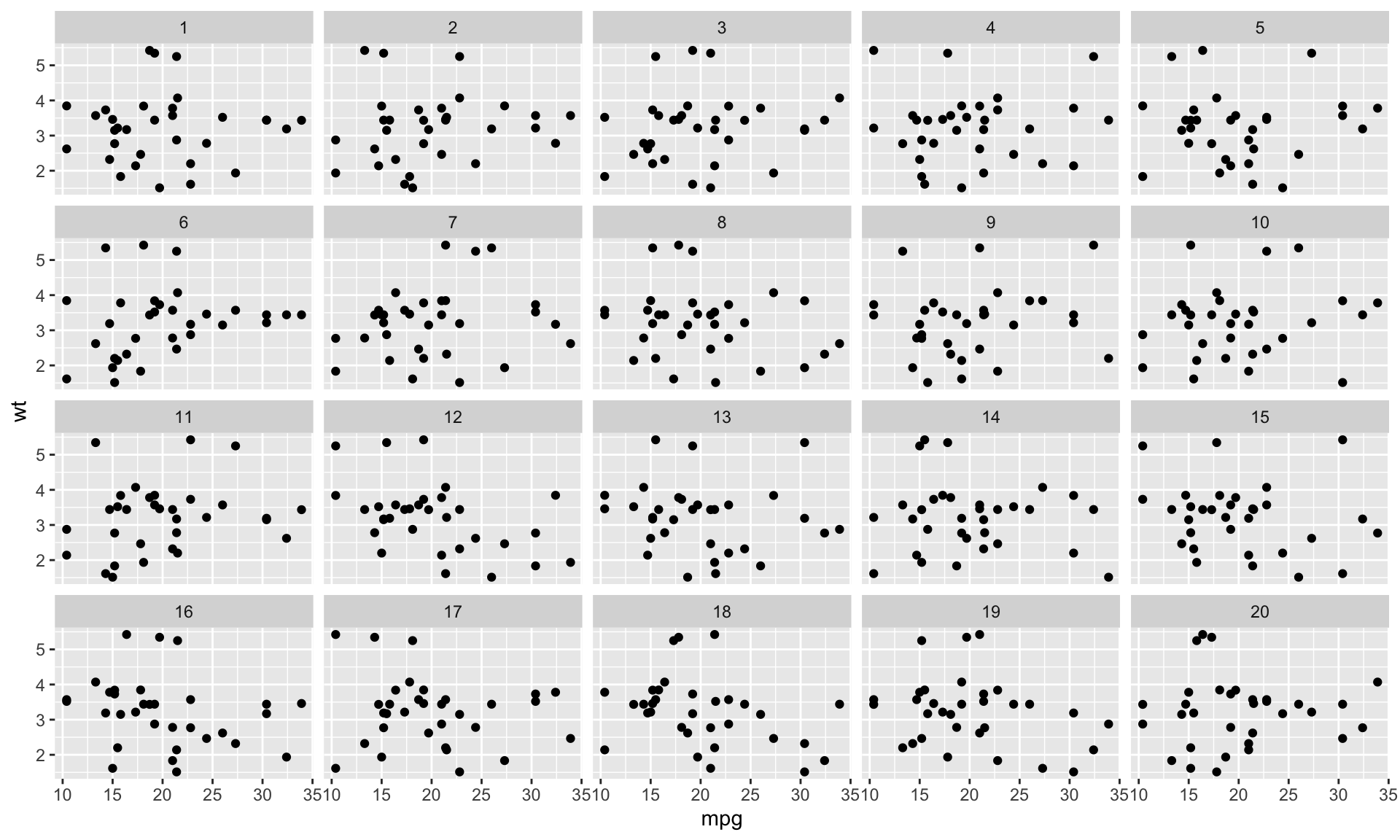
Will the real mtcars please stand up?
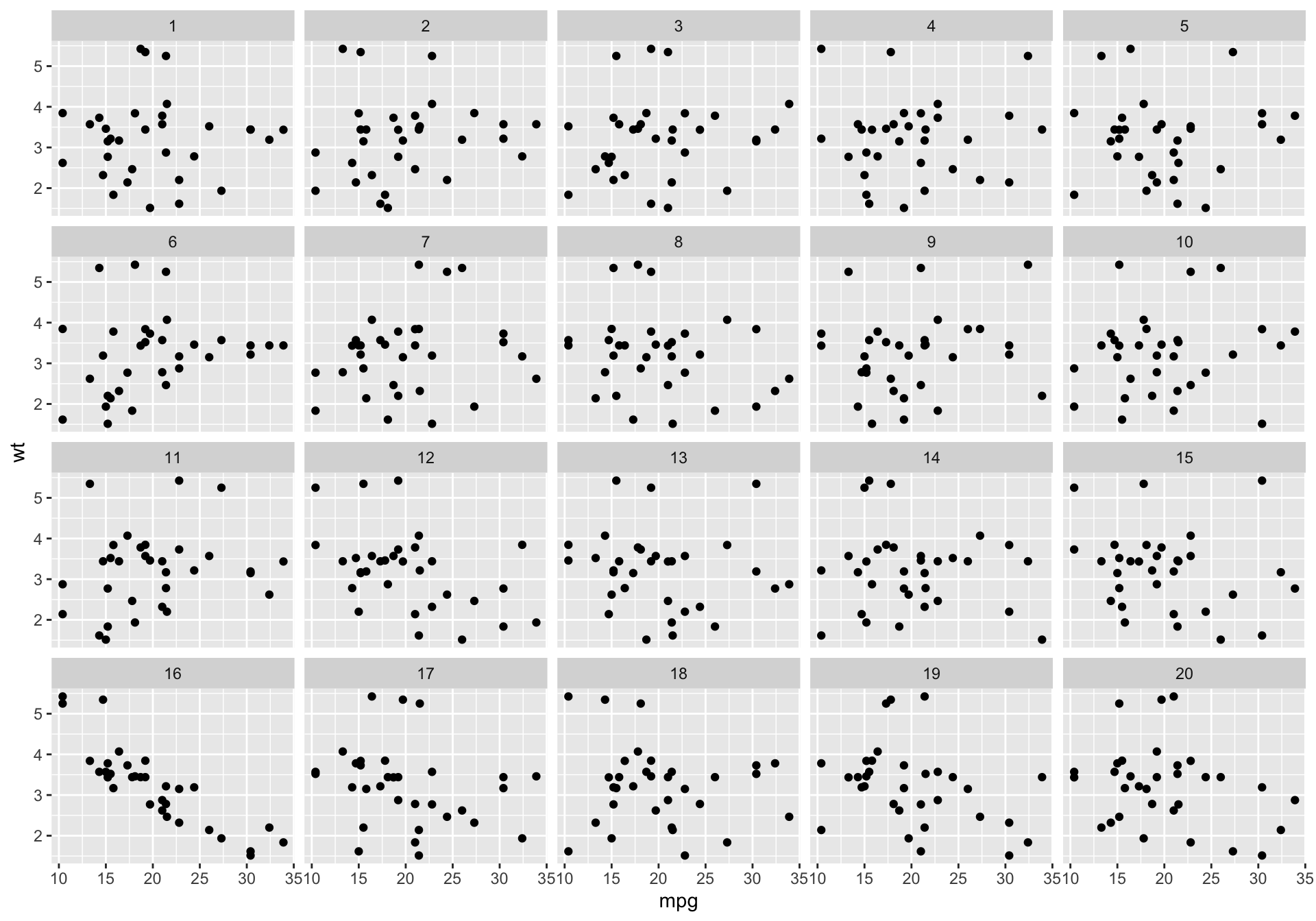
The making of the lineup III
Step 3. Plot the permutations
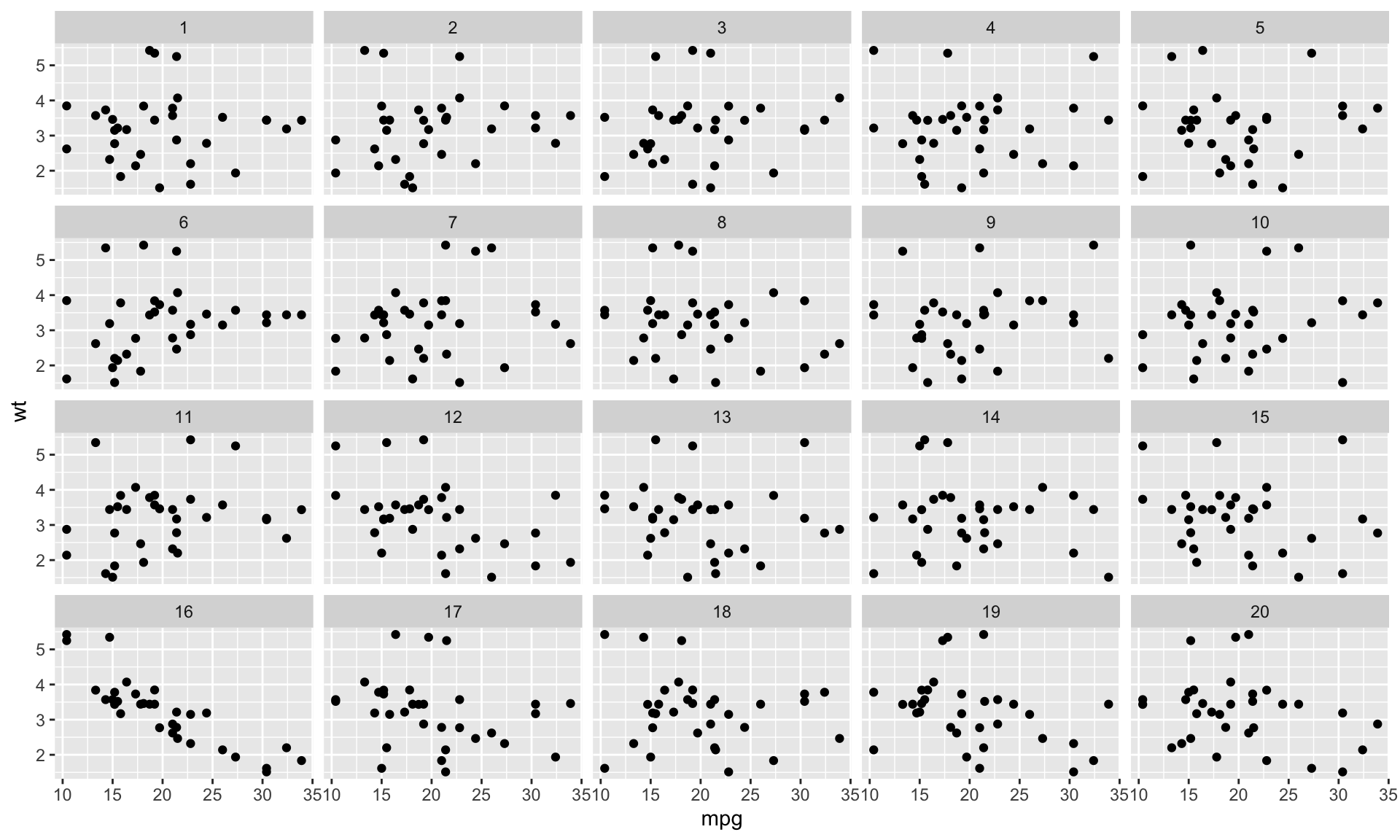
Train your eyes to spot the real mtcars
The making of the rorschach III
Step 3. Plot the permutations
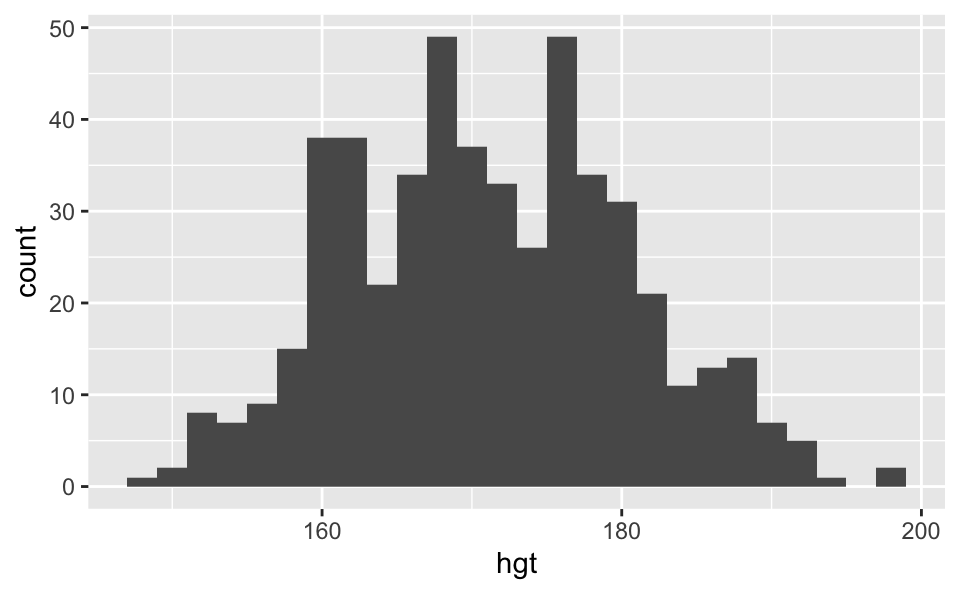
Case study: Heights of adults
The following histogram shows the distribution of heights of 507 physically active individuals (openintro::bdims$hgt). Do the heights of these individuals follow a normal distribution?
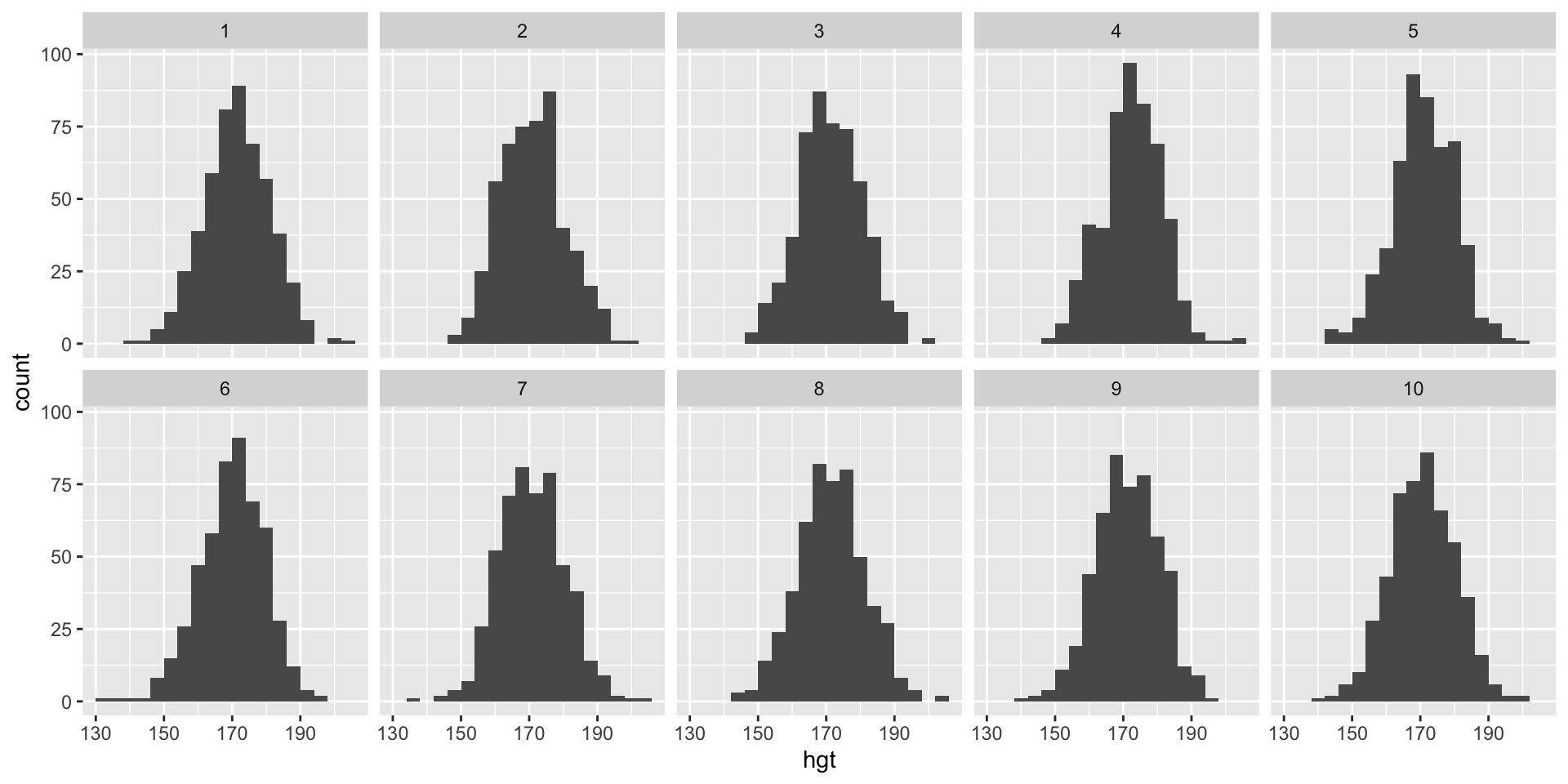
Spot the real data
Which of the following is the plot of the real data? (Note: A different binwidth than the previous plot is used.)
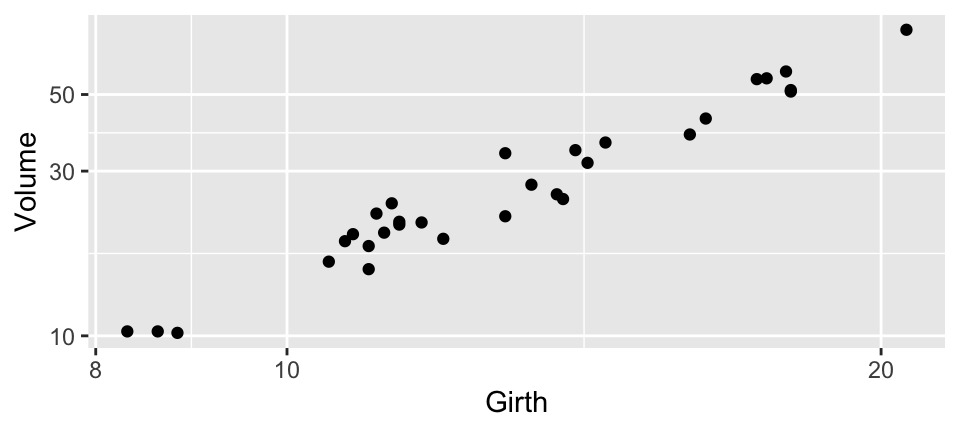
Case study: Black cherry trees
Plot
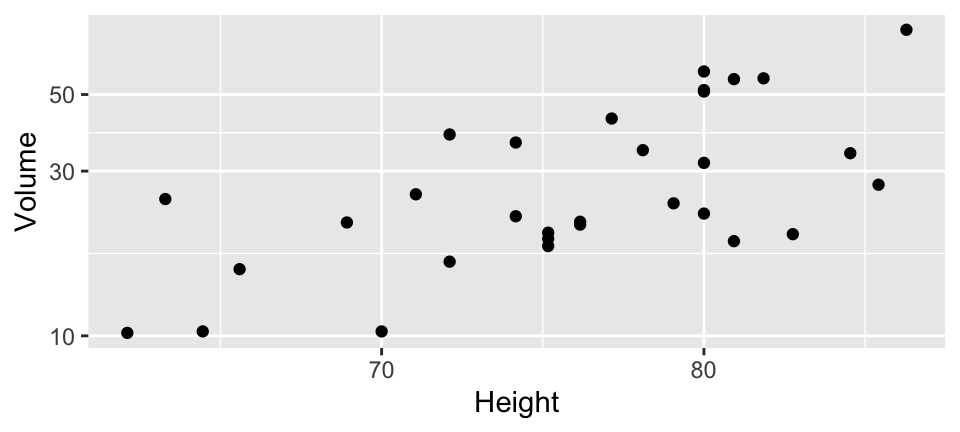
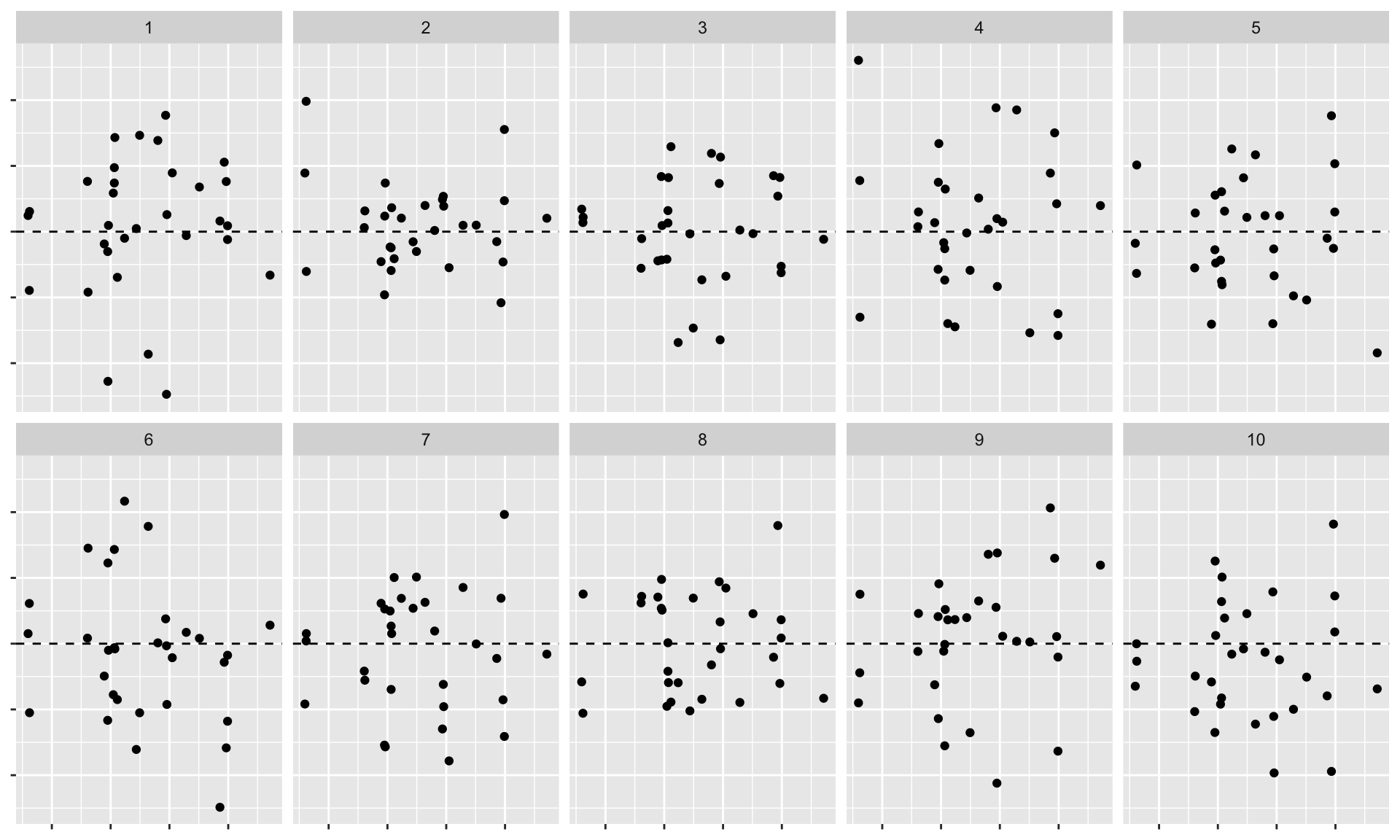
Lineup
Which one is the real residuals plot?
Acknowledgements
- Statistical inference for exploratory data analysis and model diagnostics by Andreas Buja , Dianne Cook , Heike Hofmann , Michael Lawrence , Eun-Kyung Lee , Deborah F. Swayne, and Hadley Wickham
- Graphical Inference for Infovis by Hadley Wickham, Dianne Cook, Heike Hofmann, and Andreas Buja
- Using computational tools to determine whether what is seen in the data can be assumed to apply more broadly by Emi Tanaka
- Extending beyond the data, what can and cannot be inferred more generally, given the data collection by Emi Tanaka
- The nullabor package